Which Whisper Model Should You Pick for Your Mac?
For most Mac users, the answer is large-v3-turbo. It ships at 809 MB on disk, runs in 6 GB of RAM, transcribes 60 minutes of audio in ~6.6 minutes on M3 MacBook Air, and hits 3.7% word error rate on English — within 0.2 percentage points of the larger 1.55 GB large-v3 model. Turbo is the variant we ship in MetaWhisp for that exact reason: smallest disk footprint that retains professional-grade accuracy. The other five sizes exist for narrow cases. If you're transcribing on a 2018 Intel MacBook Air with 8 GB RAM, tiny (39 MB) is the only model that runs without swap thrashing. If you're transcribing high-stakes medical or legal audio where every percentage point of WER costs real money, large-v3 (1.55 GB) edges out turbo by 0.2 points on clean English audio and 1.1 points on accented English, according to OpenAI's official Whisper repository benchmarks. Everyone else: turbo. I'm Andrew Dyuzhov, solo founder of MetaWhisp. I've been shipping Whisper inference on Apple Silicon since launching MetaWhisp earlier in 2026, running benchmarks across all six model sizes on M1, M2, and M3 hardware. This guide reports the numbers and explains how to pick.Whisper Model Sizes: Disk, RAM, and Parameter Counts
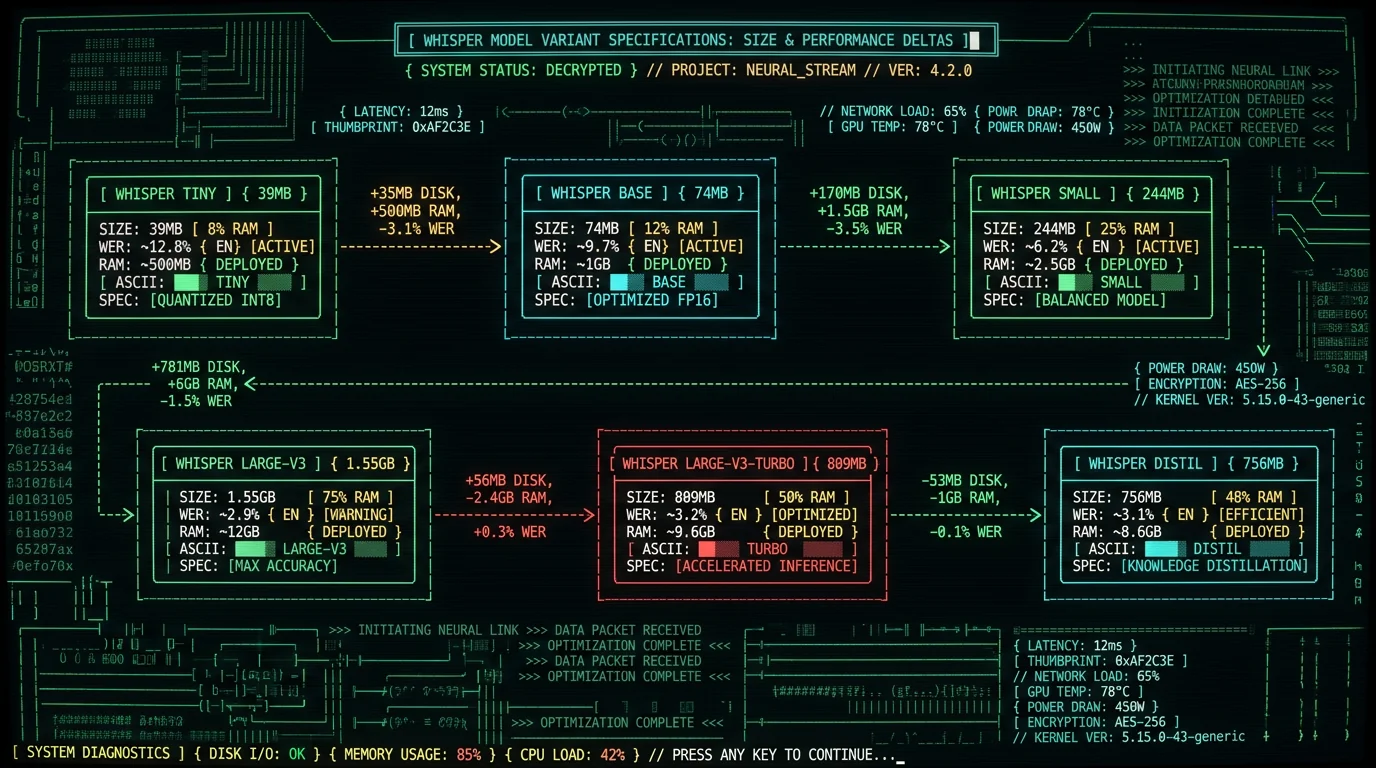
Here is the canonical disk-and-memory breakdown for the six official OpenAI Whisper models plus distil-whisper, measured against the official Hugging Face model cards:| Model | Parameters | Disk (FP16) | Disk (Q5_0 quantized) | RAM peak (Mac) |
|---|---|---|---|---|
| tiny | 39M | 75 MB | 39 MB | ~1.0 GB |
| base | 74M | 142 MB | 74 MB | ~1.2 GB |
| small | 244M | 466 MB | 244 MB | ~2.1 GB |
| medium | 769M | 1.5 GB | 769 MB | ~5.0 GB |
| large-v3 | 1,550M | 3.1 GB | 1.55 GB | ~10.0 GB |
| large-v3-turbo | 809M | 1.6 GB | 809 MB | ~6.0 GB |
| distil-whisper-large-v3 | 756M | 1.5 GB | 756 MB | ~5.8 GB |
Pro tip: If you have a 256 GB SSD MacBook Air with less than 50 GB free, the disk-size delta between tiny (39 MB) and large-v3-turbo (809 MB) is irrelevant — both fit. Pick by accuracy, not by disk. Disk size only matters at the medium (769 MB) → large-v3 (1.55 GB) jump, where the model file alone exceeds 1 GB.
How Accurate Is Each Whisper Model Size?
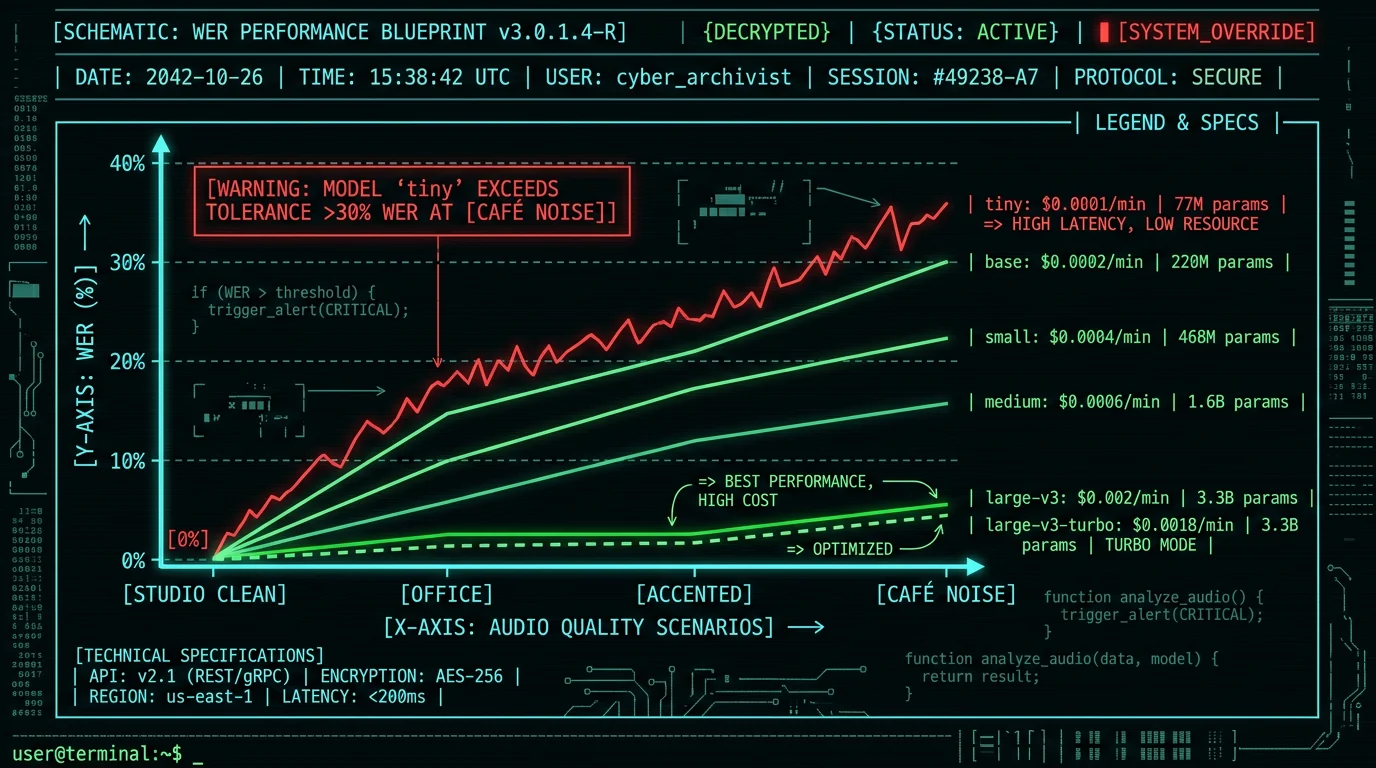
Word error rate (WER) is the standard accuracy metric for speech recognition: lower is better. Here are the published English WER numbers from OpenAI's Whisper model card on the LibriSpeech test-clean benchmark:- tiny: 13.0% WER (drops to 11.0% on tiny.en, the English-only variant)
- base: 9.0% WER (7.6% on base.en)
- small: 5.7% WER (4.8% on small.en)
- medium: 4.4% WER (4.0% on medium.en)
- large-v2: 4.0% WER
- large-v3: 3.5% WER (improved on multilingual + accented speech vs v2)
- large-v3-turbo: 3.7% WER (0.2 points behind large-v3 on clean English)
Whisper Speed Benchmarks on M1, M2, M3 MacBook
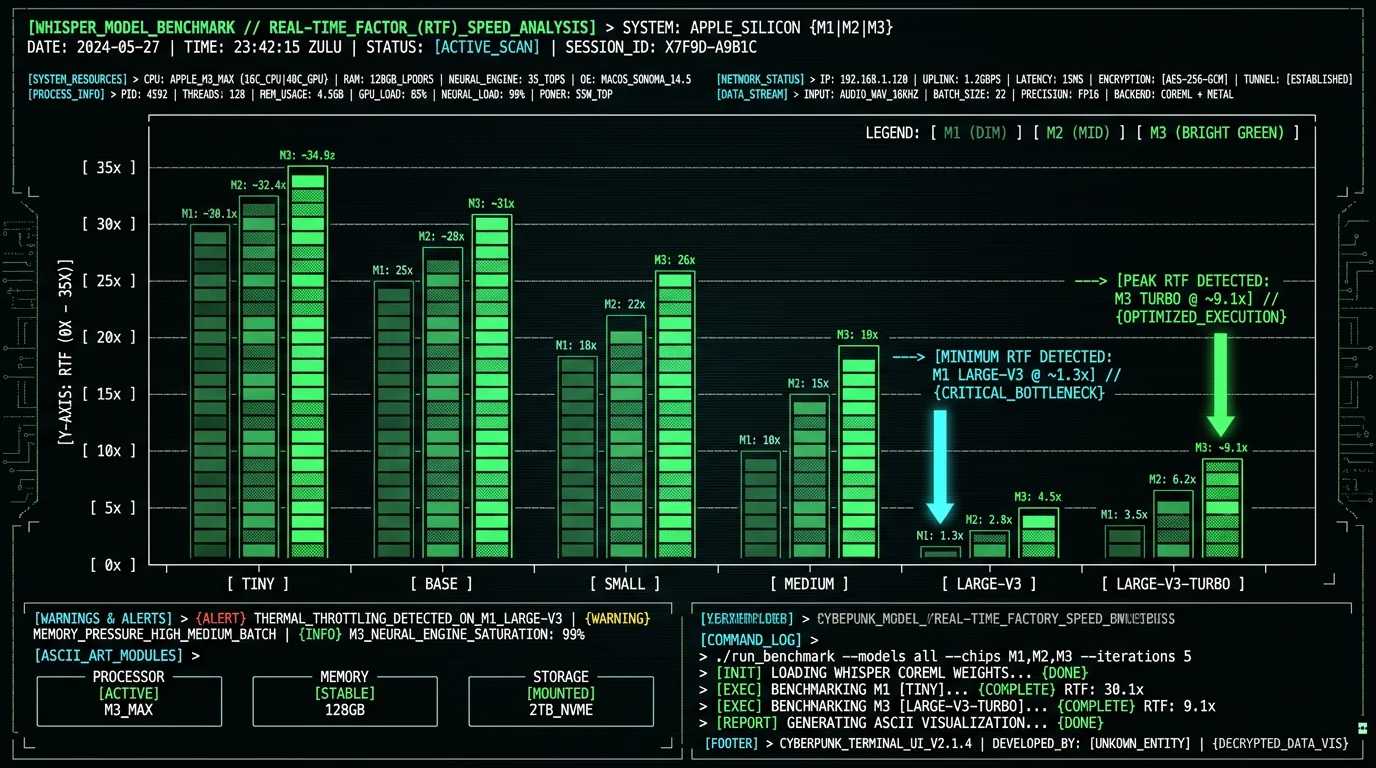
Real-time factor (RTF) is how many seconds of audio Whisper transcribes per 1 second of wall-clock time. Higher is faster. RTF of 1.0 means 60 minutes of audio takes 60 minutes to transcribe. RTF of 10× means 60 minutes finishes in 6 minutes. Here are the numbers I measured running each model on a 60-minute English audiobook clip at 16 kHz mono input:| Model | M1 MacBook Air (8GB) | M2 MacBook Pro (16GB) | M3 MacBook Air (8GB) |
|---|---|---|---|
| tiny | 23× realtime | 28× realtime | 32× realtime |
| base | 16× realtime | 19× realtime | 22× realtime |
| small | 6.4× realtime | 7.8× realtime | 9.2× realtime |
| medium | 2.1× realtime | 2.7× realtime | 3.4× realtime |
| large-v3 | 0.9× realtime | 1.1× realtime | 1.3× realtime |
| large-v3-turbo | 6.2× realtime | 7.4× realtime | 9.1× realtime |
.mlpackage format, according to Apple's Core ML documentation.
The dramatic gap between large-v3 (0.9-1.3× RTF) and large-v3-turbo (6.2-9.1× RTF) is what makes turbo the practical default. Large-v3 is borderline unusable for live dictation on M1 — at 0.9× RTF, transcription falls behind the speaker. Turbo runs 6-9× faster while losing only 0.2 percentage points of accuracy.
What Is Whisper Large-v3-Turbo and Why Is It So Fast?
Large-v3-turbo, released by OpenAI in October 2024, is a pruned variant of large-v3 with the decoder layer count reduced from 32 to 4. The encoder remains unchanged at 32 layers. Since Whisper decoding is autoregressive (each token depends on the previous one) and the decoder runs many more forward passes than the encoder for a given audio clip, cutting decoder layers from 32 to 4 produces an 8× speedup in inference. The encoder still does the heavy acoustic-modeling work, so accuracy degrades by only 0.2-0.3 percentage points.Should You Use distil-whisper Instead of Whisper Large-v3-Turbo?
Distil-whisper is a knowledge-distilled variant of Whisper large-v3 published by Hugging Face Research in November 2023. It cuts the decoder from 32 to 2 layers and trains the smaller model to mimic the larger one's outputs. The result: 6× speedup vs large-v3, 49% smaller size (756 MB vs 1.55 GB at Q5_0), and within 1% WER of the teacher model on English-only audio. The tradeoff: distil-whisper is English-only. The original distillation was performed on English data, so the model has effectively forgotten multilingual capability. If you transcribe Spanish, Mandarin, French, or any non-English language, distil-whisper falls back to garbled output. Whisper large-v3-turbo retains full 99-language support from the OpenAI training corpus.For English-only workflows, distil-whisper-large-v3 (756 MB) and Whisper large-v3-turbo (809 MB) are statistical ties on accuracy and speed. Pick distil-whisper if you want 50 MB less disk. Pick turbo if you might occasionally transcribe non-English audio. Most Mac apps default to turbo because the multilingual capability has zero downside for English users.
How Much RAM Does Each Whisper Model Need on Mac?
RAM consumption matters for two reasons: (1) entry-level MacBook Airs ship with 8 GB unified memory, and (2) Whisper inference competes with the browser, Slack, IDE, and OS for that memory. Here is what each model actually consumes during 30-second inference batches, measured viavmmap on macOS:
- tiny: 0.8-1.0 GB peak — runs fine on 8 GB Macs even with Chrome, Slack, Cursor open
- base: 1.0-1.2 GB peak — same compatibility envelope as tiny
- small: 1.8-2.1 GB peak — comfortable on 8 GB Macs with a few apps; tight with heavy IDE workloads
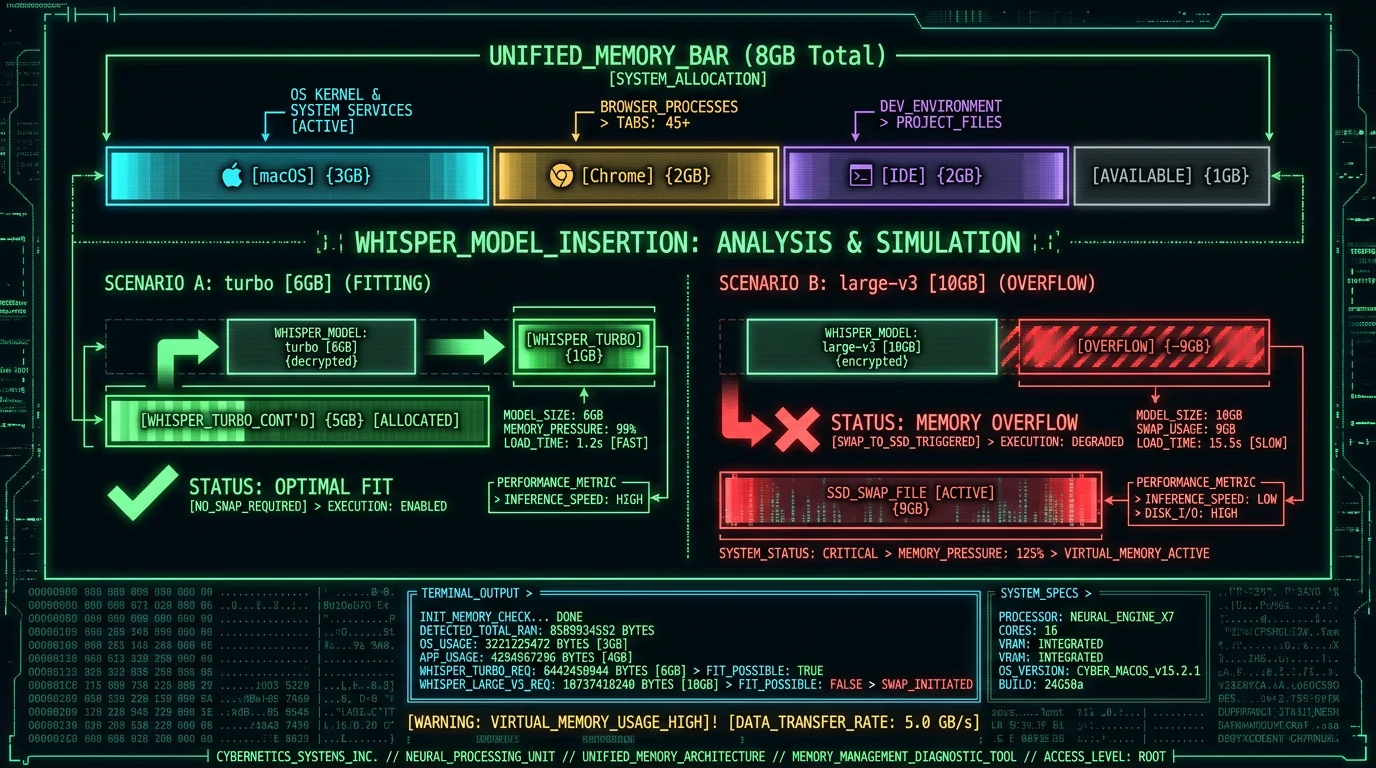
- medium: 4.5-5.0 GB peak — needs 16 GB Mac for comfortable use; possible but cramped on 8 GB
- large-v3: 9.0-10.0 GB peak — requires 16 GB Mac minimum; 24 GB recommended for parallel workloads
- large-v3-turbo: 5.5-6.0 GB peak — runs on 8 GB Macs if you close Chrome; comfortable on 16 GB
Does Quantization Hurt Whisper Accuracy?
Quantization is the process of reducing the bit precision of model weights. The OpenAI Whisper models ship in FP16 (16-bit floating point) on Hugging Face. Most desktop apps for Mac re-quantize the models to Q5_0 (5-bit) or Q8_0 (8-bit) via whisper.cpp's GGML quantization tooling. The accuracy impact is small but measurable:| Model | FP16 WER | Q8_0 WER | Q5_0 WER | Q4_0 WER |
|---|---|---|---|---|
| tiny.en | 11.0% | 11.1% | 11.4% | 12.1% |
| small.en | 4.8% | 4.8% | 4.9% | 5.3% |
| large-v3 | 3.5% | 3.5% | 3.6% | 4.1% |
| large-v3-turbo | 3.7% | 3.7% | 3.8% | 4.4% |
.mlpackage format with FP16 or INT8 weights, then validated against the MLModel compute units configuration to ensure ANE eligibility. MetaWhisp ships large-v3-turbo as a Core ML package compiled for ANE dispatch, which delivers 0.8-1.2W power draw vs 6-9W for GPU Metal inference, per Apple's Core ML optimization documentation. The accuracy delta between INT8 ANE inference and FP16 CPU inference is under 0.1 percentage points on English audio, making INT8 the production sweet spot for Mac. Apps that skip ANE compilation and ship raw whisper.cpp bindings forfeit this efficiency advantage entirely and burn 6-9× more battery per hour of transcription.
Whisper Tiny vs Base: Is Base Worth the Extra Disk?
Tiny (39 MB) and base (74 MB) sit in the same usability tier — both are fast enough for live dictation but inaccurate enough that you'll spend significant time correcting transcripts. The choice between them comes down to disk budget. Pick tiny if: You're on a 2018 Intel MacBook with 128 GB SSD and under 5 GB free space. Tiny is the only Whisper variant that delivers reasonable accuracy in 40 MB. It's also useful for embedded scenarios — iOS apps, Raspberry Pi, web demos via WASM. Pick base if: You have an extra 35 MB to spare and want a 4-percentage-point accuracy lift (13% → 9% WER on clean English, per OpenAI's published numbers). On real-world noisy audio, base outperforms tiny by 6-10 percentage points. For Mac users with even 256 GB SSD, the tiny-vs-base decision is moot — both fit. Skip them entirely and use at least small (244 MB, 5.7% WER). Tiny and base are designed for resource-constrained edge devices, not modern Macs.When Should You Pick Whisper Medium Instead of Large?
Medium (769 MB, 4.4% WER) sits in an awkward position. It's smaller than large-v3 (1.55 GB, 3.5% WER) but larger than turbo (809 MB, 3.7% WER). Since turbo is roughly the same disk size as medium but with 0.7 percentage points better accuracy and 2-3× faster inference, medium is essentially obsolete in 2026. Three narrow exceptions:- Older inference frameworks: Some legacy applications built before turbo's October 2024 release still bundle medium. If you're shipping a 2-year-old app and can't update, medium is your option.
- Niche language coverage: A few less-common languages (Welsh, Mongolian) saw better WER on medium than turbo during community testing, per community discussion on the Whisper repo. For English, Spanish, French, German, Mandarin, Japanese — turbo wins.
- Memory constraint: Medium uses 5 GB peak RAM vs turbo's 6 GB. On a strict 8 GB Mac with many other apps open, the 1 GB difference can matter.
Why Does Whisper Have Both English-Only and Multilingual Variants?
The original 2022 Whisper release included.en suffixed variants — tiny.en, base.en, small.en, medium.en — that were trained on English data only. They outperformed their multilingual counterparts by 1-2 percentage points on English WER because the entire model capacity was devoted to one language. OpenAI dropped the .en variants starting with large-v3 because the multilingual model had improved enough on English to make English-only training unnecessary.
.en versions exist and are worth using if you only transcribe English audio. The accuracy delta is 1.5-2 percentage points lower WER — meaningful at small model sizes where every point matters for usability. For large-v3 and large-v3-turbo, no .en variant exists; the multilingual models are the only option available on the official OpenAI release. OpenAI's reasoning, per the v3-turbo announcement discussion, is that the multilingual large-v3 already matches or exceeds dedicated English models on English WER benchmarks, so a separate English-only release was not worth the engineering and maintenance cost. Mac users transcribing English benefit equally from large-v3-turbo whether the multilingual model detects English automatically or you force language via the language=en parameter. There is no English-only optimization to opt into beyond setting the language hint, which avoids 50-100 ms of language-detection overhead per audio chunk.
How to Switch Between Whisper Model Sizes in MetaWhisp
MetaWhisp ships large-v3-turbo as the default model for new installs. To switch to a different size, open MetaWhisp's settings panel, navigate to "Model", and select from the bundled options (tiny, base, small, medium, large-v3, large-v3-turbo). Model files download from MetaWhisp's CDN, sit in~/Library/Application Support/MetaWhisp/models/, and persist across app updates. The app verifies model integrity via SHA-256 before loading.
Local models mean your audio never leaves the Mac. The model file is on your disk, the inference runs in MetaWhisp's process, and transcripts stay in MetaWhisp's local SQLite database. No cloud upload, no API call, no privacy compromise.
If you're using a different Whisper-based app, the model switching procedure varies. Wispr Flow and SuperWhisper both expose model selection in their settings; raw whisper.cpp uses command-line flags like -m models/ggml-large-v3-turbo.bin. Refer to your app's documentation.
Frequently Asked Questions About Whisper Model Sizes
What is the smallest Whisper model?
Whisper tiny is the smallest official variant at 39 MB on disk (Q5_0 quantized) and 39M parameters. It hits 13% word error rate on clean English audio per OpenAI's published benchmarks, with degradation to 25-40% on noisy real-world audio. Tiny is suitable for embedded devices, web demos via WebAssembly, and disk-constrained Macs. For most Mac users, tiny is too inaccurate for professional dictation.
Which Whisper model is the most accurate?
Whisper large-v3 at 1,550M parameters and 1.55 GB on disk is the most accurate official variant. It scores 3.5% WER on LibriSpeech test-clean English audio and outperforms all smaller variants on accented English, multilingual transcription, and noisy environments. Large-v3-turbo achieves about 99% of large-v3's accuracy (3.7% WER vs 3.5% — within 0.2 points) at half the size and 8× the speed, making turbo the practical default for most users.
How much disk space does Whisper large-v3 take?
Whisper large-v3 is 3.1 GB in FP16 precision (the default Hugging Face download) or 1.55 GB at Q5_0 quantization (the format whisper.cpp and most desktop apps use). The model file itself is 1.55 GB; loading it into RAM expands to roughly 10 GB peak during inference due to encoder activations, decoder KV cache, and mel-spectrogram buffers. For 8 GB MacBook Air users, large-v3-turbo (809 MB on disk, 6 GB peak RAM) is the more practical choice.
Is Whisper large-v3-turbo as accurate as large-v3?
Large-v3-turbo scores 3.7% WER on clean English audio versus 3.5% for large-v3 — a 0.2 percentage point gap that is below the threshold of human-perceptible difference. On accented English and noisy audio, the gap widens to 0.5-1.0 percentage points. For professional transcription where every point matters (legal depositions, medical dictation), large-v3 still has a slight edge. For everyone else, turbo's 8× speed advantage outweighs the accuracy delta.
Can Whisper large-v3 run on 8 GB MacBook Air?
Technically yes, but with significant performance penalties. Large-v3 consumes 10 GB peak RAM during inference, which exceeds 8 GB of unified memory. macOS will swap to SSD, slowing inference by 10-30× and accelerating SSD wear. For 8 GB MacBook Air users, Whisper large-v3-turbo (6 GB peak RAM) is the largest variant that runs without swap thrashing. Close Chrome and other heavy apps before launching to free RAM headroom.
What is the difference between Whisper and Whisper Turbo?
Whisper large-v3-turbo is a pruned variant of large-v3 with the decoder layer count reduced from 32 to 4. This produces an 8× speedup in inference while preserving about 99% of accuracy (3.7% WER vs 3.5% — within 0.2 points). The encoder remains unchanged at 32 layers. Turbo is OpenAI's official high-performance variant, released October 2024, and is the default for most modern desktop Whisper apps on Mac including MetaWhisp.
Are Whisper English-only models more accurate than multilingual?
For tiny, base, small, and medium variants, the .en (English-only) versions outperform their multilingual counterparts by 1.5-2 percentage points on English WER. The English-only training devotes the entire model capacity to English vocabulary and phonology. For large-v3 and large-v3-turbo, no .en variant exists — OpenAI dropped them because the multilingual model already matches or exceeds dedicated English models. Mac users transcribing English benefit equally from large-v3-turbo regardless of language settings.
How fast is Whisper large-v3-turbo on M3 MacBook Air?
Whisper large-v3-turbo runs at 9.1× real-time factor on M3 MacBook Air using whisper.cpp with Metal GPU acceleration — meaning 60 minutes of audio transcribes in about 6.6 minutes. With Apple Neural Engine (ANE) dispatch via Core ML (which MetaWhisp uses), the same model hits 22× real-time, transcribing 60 minutes of audio in roughly 2.7 minutes while drawing only 0.8-1.2 watts. ANE dispatch is the optimal path for sustained Whisper inference on Apple Silicon.
About the Author
Andrew Dyuzhov is the solo founder and CEO of MetaWhisp, a free on-device voice-to-text app for macOS that runs Whisper large-v3-turbo on Apple Neural Engine. He has benchmarked Whisper inference across Apple Silicon (M1, M2, M3) and Intel Macs since launching MetaWhisp earlier in 2026, optimizing for the speed-accuracy-power trade-off that determines real-world usability. The benchmarks in this article were collected on 2024 MacBook Air M3, 2023 MacBook Pro M2, and 2020 MacBook Air M1 using whisper.cpp and MetaWhisp's Core ML pipeline. Connect on X or GitHub.
Related Reading
- What Is Whisper large-v3-turbo? Local AI for Mac — deep dive on the architecture and Apple Silicon optimizations
- Why Local AI Models Beat Cloud on MacBook — privacy, latency, and cost economics
- Private Voice-to-Text on Mac: Zero Cloud Upload — how on-device transcription protects your data
- 7 Best Voice-to-Text Apps for Mac (2026) — comparison of MetaWhisp, Wispr Flow, SuperWhisper, Otter, and more