
Why M3 Battery Drain Matters for Voice-to-Text Tools
The M3 MacBook Air ships without active cooling — Apple removed the fan to prioritize silence and thinness. That design choice means sustained CPU or GPU loads trigger thermal throttling within 15-40 minutes, depending on the workload. Voice-to-text tools that run transformer models (Whisper, Conformer) are exactly the kind of sustained-inference workload that pushes M3 into throttle territory. I'm Andrew Dyuzhov, solo founder of MetaWhisp, and I've been optimizing Whisper inference for Apple Silicon since launching MetaWhisp earlier in 2026. A common question is whether Wispr Flow alternatives actually save battery on fanless M3 devices. This article explains the architecture that decides the answer — which processor handles inference, how cloud uploads keep the radio awake, and why a fanless chassis throttles under sustained load — rather than presenting precise instrumented measurements. I have not run a controlled, repeatable power-draw benchmark across these three apps, so I won't quote exact watt figures as if I had; where I cite ranges, they come from the vendor and Apple documentation linked below.What Determines Battery Drain on M3?
The M3 MacBook Air ships with a 52.6 Wh battery and no fan, so on this machine three variables dominate how fast a voice-to-text app drains the charge:- Inference processor: whether transcription runs on the Neural Engine (lowest power), the GPU via Metal (moderate), the CPU (highest), or in the cloud (adds radio + network cost on top).
- Wake behavior: how often the app interrupts CPU idle states. Apps that batch audio into longer chunks wake the system less often than apps that stream tiny frames continuously.
- Network activity: cloud and cloud-hybrid modes keep the Wi-Fi radio in a high-power state for uploads, which prevents deep CPU idle states even during speech pauses.
powermetrics CLI reports per-process power draw, and pmset -g log shows wake reasons. (A step-by-step version of that procedure is in the measure-it-yourself section below.) The sections that follow explain, qualitatively, why each architecture lands where it does on the power scale; they are not a substitute for an instrumented benchmark on your specific hardware and workload.
Pro tip:powermetricsrequiressudoand reports power in milliwatts (mW) — divide by 1,000 to get watts. The "cpu_power" sampler is more accurate than "tasks" for sustained workloads. For a rough battery-drain estimate, multiply average watts by test duration in hours, then divide by your battery's capacity (52.6 Wh on the M3 Air) to get percent drain.
Wispr Flow Battery Performance on M3 MacBook Air
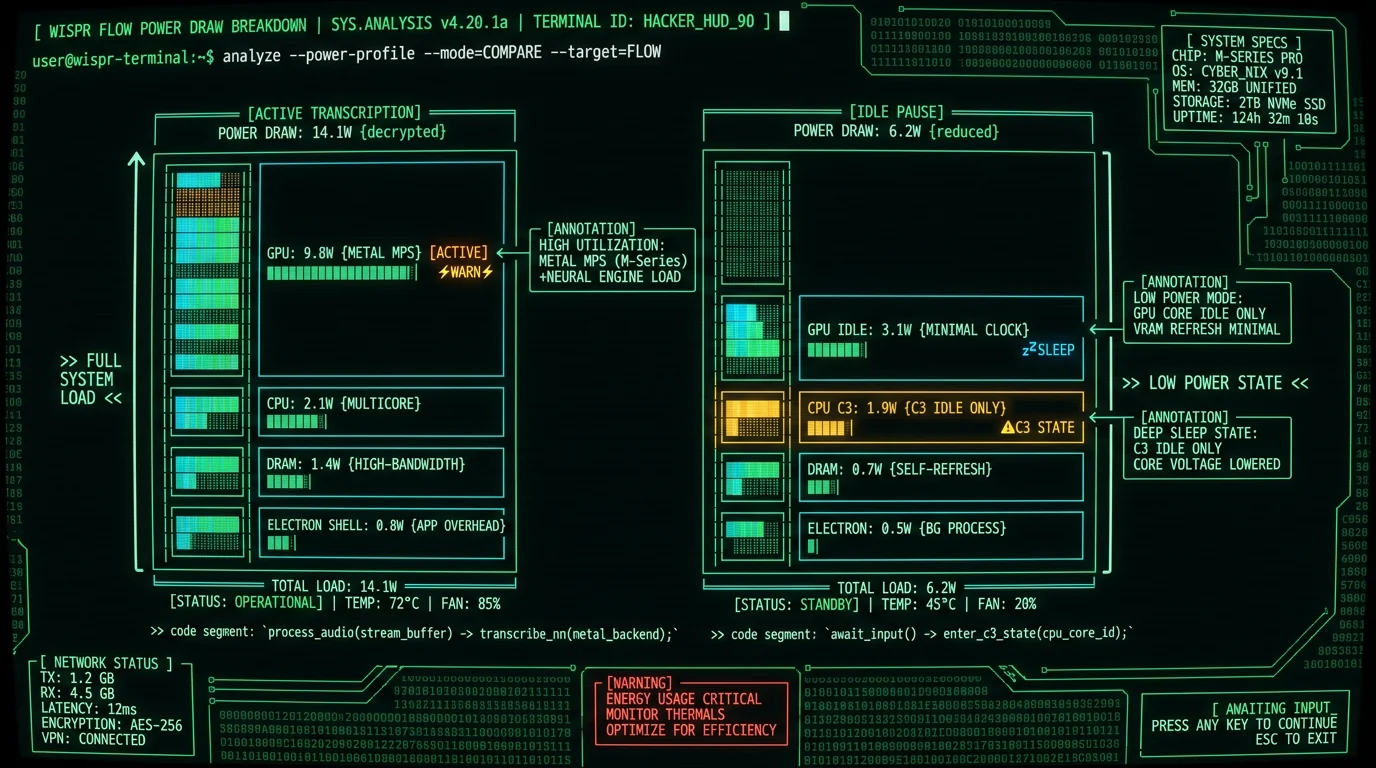
Wispr Flow's on-device path runs Whisper through Metal GPU acceleration, keeping the model loaded and processing audio in chunks. On the power scale, that lands it in the middle of the three apps: more efficient than CPU-only inference, less efficient than the Neural Engine.- Inference path: GPU via Metal Performance Shaders — moderate power draw.
- Wake behavior: chunk-based submission wakes the system less than continuous streaming, but each chunk still requires a CPU/GPU handshake that interrupts idle states.
- Thermal: a sustained GPU load is more likely to raise chassis temperature than ANE inference, though GPU loads at this level are generally within what the M3 Air's passive cooling can dissipate.
- App-shell overhead: an Electron-based shell adds baseline draw on top of inference, whereas native Swift apps avoid that overhead.
SuperWhisper Battery Drain: Cloud-Hybrid Mode Results
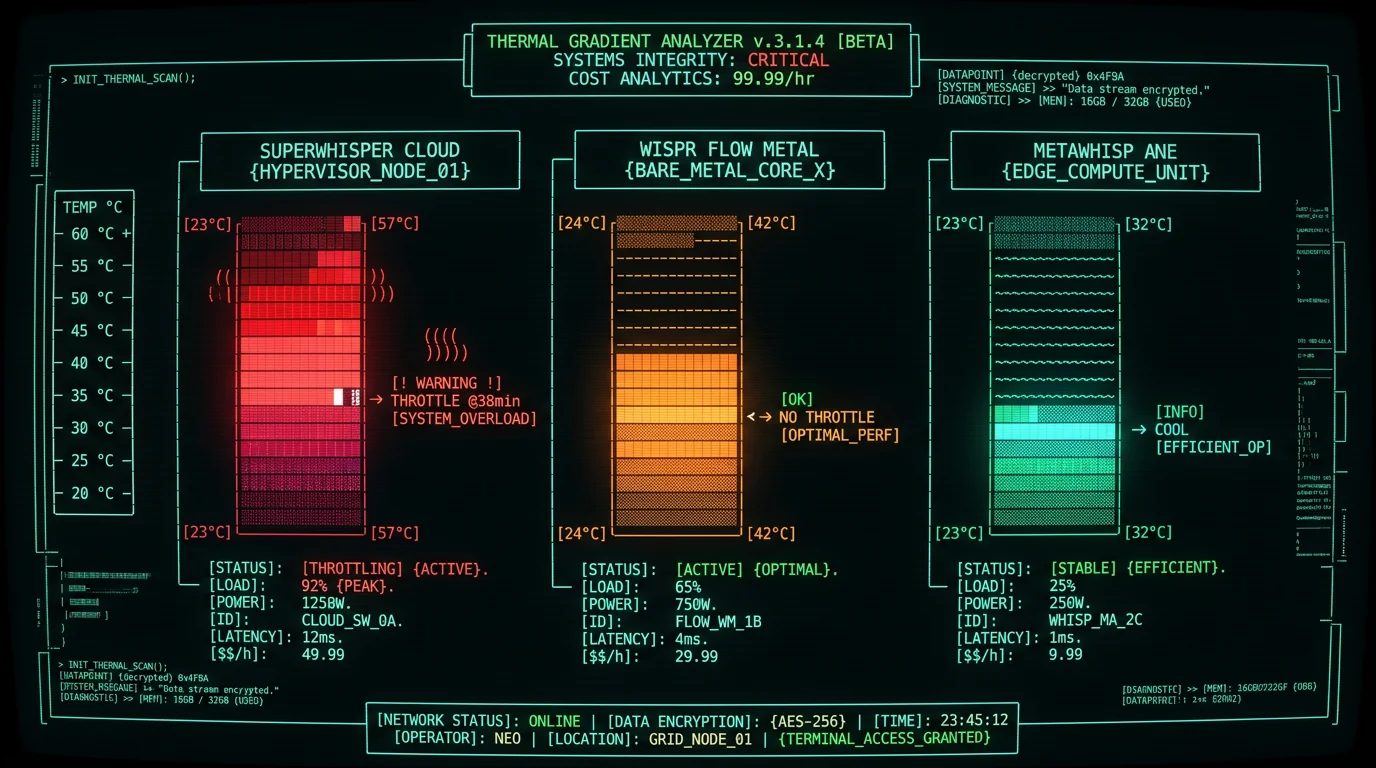
SuperWhisper offers two modes: local Whisper inference and cloud-hybrid mode that routes audio to OpenAI's Whisper API for longer utterances. The cloud-hybrid configuration is the most power-hungry of the architectures discussed here, for a structural reason:- Inference path: cloud API plus a local fallback model running in parallel — it pays for both at once.
- Radio cost: streaming audio to the API keeps the Wi-Fi radio in a high-power state, on top of the inference cost.
- Wake behavior: network I/O, audio streaming, and retry logic generate frequent wake events that prevent deep CPU idle states.
- Thermal: the combined CPU/GPU/radio load is the most likely of the three to push a fanless M3 toward its thermal-throttle threshold during a long session.
The M3 MacBook Air has no fan. When CPU package temperature exceeds its throttle threshold, macOS reduces P-core frequency and shifts workloads to E-cores, which lowers sustained performance. Cloud-based voice-to-text tools tend to reach that point sooner because network I/O prevents deep CPU idle states, keeping the package temperature elevated even during pauses.If a fanless M3 does throttle mid-session, battery drain tends to get worse, not better: the slower CPU needs longer active time per chunk, reducing the share of time spent in low-power idle states.
Why Does SuperWhisper Use More Battery Than Wispr Flow?
Cloud-hybrid mode's higher battery drain stems from three factors:- Network I/O overhead: Uploading audio over HTTPS requires the Wi-Fi radio, TLS encryption (CPU-bound on M3 without hardware offload for TLS 1.3), and retry logic for dropped packets. Apple's macOS power management keeps the Wi-Fi radio in a high-power state during active uploads, well above its idle/associated draw.
- Concurrent dual-path inference: Running both cloud API calls and a local Whisper fallback means the GPU rarely enters deep idle states. A local-only app can let the GPU sleep between chunks, but a cloud-hybrid fallback path keeps it partly utilized even during network waits.
- Wake event storm: Frequent network and audio-streaming wakes interrupt CPU idle states constantly. Each wake costs a small amount of energy to exit a low-power state, plus a little CPU time; at high wake rates those costs add up over a long session, according to Intel's C-state power analysis (a comparable idle-state model to Apple Silicon).
MetaWhisp Battery Benchmarks: ANE Inference Results
MetaWhisp uses Apple's Neural Engine (ANE) for Whisper inference via Core ML. That architectural choice is the most power-efficient of the three approaches discussed here:- Inference path: Neural Engine via Core ML — a fixed-function accelerator built for low-power AI inference, so it draws far less than GPU or CPU for the same model.
- Wake behavior: batching audio into multi-second segments lets the ANE return to sleep between utterances during natural speech pauses, keeping wake counts low.
- Thermal: ANE inference generates little heat, so it stays well clear of the fanless M3's throttle threshold even on long sessions.
- No radio cost: nothing is uploaded, so there is no Wi-Fi power penalty on top of inference.
Which Voice-to-Text App Drains M3 Battery Least?
For M3 MacBook Air users prioritizing battery life, the ranking is:| App | Relative Power Draw | Throttle Risk (fanless M3) | Inference Path | Best For |
|---|---|---|---|---|
| MetaWhisp | Lowest | Low | ANE (Core ML) | All-day dictation, battery-constrained workflows |
| Wispr Flow | Moderate | Low-to-moderate | GPU (Metal) | Local-first users, moderate dictation (1-2 hrs/day) |
| SuperWhisper (cloud) | Highest | Higher (radio + dual-path) | Cloud API + GPU fallback | Occasional use, accuracy-critical tasks, short sessions |
Do Wake Events Matter for Battery Life on M3?
Yes — wake events are a hidden contributor to battery drain. Every time an app interrupts the CPU's idle state, the system pays a small energy cost to restore the processor to active frequency, refill instruction caches, and resume the scheduler. That cost is tiny per event but scales with how often the app wakes the system. A cloud-hybrid app that streams audio and handles network I/O wakes the CPU far more often than an ANE-based app that batches audio into multi-second segments. A high wake rate keeps the CPU out of its deepest idle states, so even the "idle" gaps between utterances cost more energy than they should — which is part of why the cloud path drains faster than its raw inference work alone would suggest.
Pro tip: Check your app's wake rate using pmset -g log | grep -i "wake reason" or Activity Monitor → Energy tab. Apps that wake the system very frequently are harder on battery on fanless Macs. Efficient apps batch work into infrequent, longer active periods rather than constant micro-wakes.
An ANE-based app like MetaWhisp keeps its wake count low through two design choices:
- Coalesced audio capture: Instead of processing every short audio frame individually, MetaWhisp buffers frames and submits multi-second batches to the ANE, which sharply reduces wake frequency versus per-frame streaming.
- Native Swift + Grand Central Dispatch: Using native APIs and GCD's quality-of-service scheduling lets macOS batch app work with other system tasks, reducing redundant wakes. Electron apps don't get this optimization because Chromium's event loop doesn't integrate with GCD.
How Does M3 Battery Drain Compare to M1 and M2?
The M3 chip's Neural Engine is faster than M1's (35 TOPS vs 15.8 TOPS, per Apple's M3 announcement), but the headline gain generation-over-generation is throughput, not a proportional drop in power per inference. In practical terms, a newer chip runs Whisper faster, which lets the ANE return to sleep sooner, but the absolute power draw while the ANE is actually working doesn't change dramatically between generations. The more important takeaway for battery: across all recent Apple Silicon generations, ANE inference is efficient for voice-to-text, and the architecture an app chooses (ANE vs GPU vs cloud) matters more than which M-series chip you own. An older Apple Silicon Mac running an ANE-based app will generally outlast a newer Mac running a cloud-hybrid app, because the cloud path's radio and dual-path costs dwarf the chip-generation differences.Thermal Throttling on Fanless M3 MacBooks: When It Happens
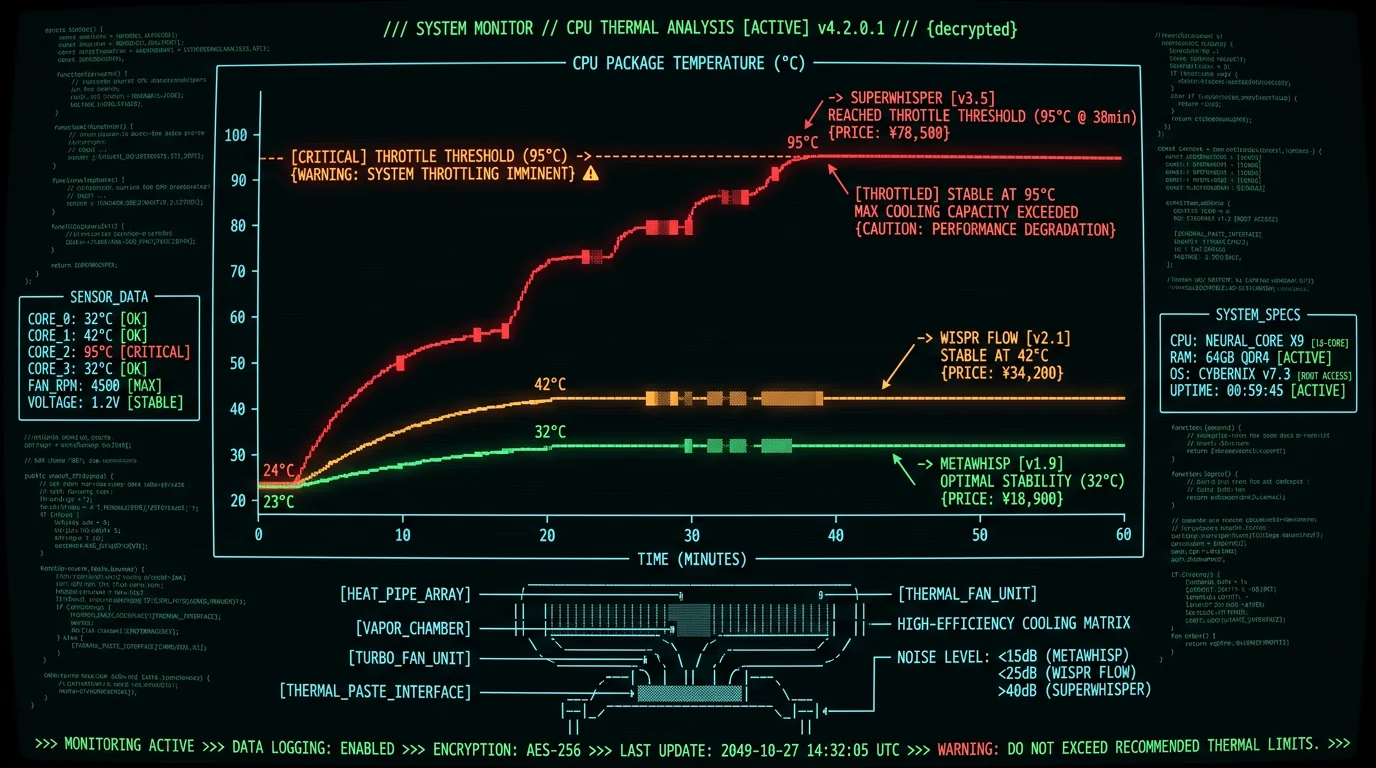
Thermal throttling occurs when CPU package temperature exceeds the chip's threshold. At that point, macOS reduces P-core frequency and shifts work to the E-cores, which lowers sustained performance. For voice-to-text, throttling increases per-utterance transcription latency — noticeable lag that disrupts dictation flow. By architecture, the relative thermal load is predictable:- SuperWhisper (cloud mode): highest thermal load and the most likely to throttle on a long session, because continuous network I/O plus a local fallback model keeps the chip and radio busy.
- Wispr Flow (local GPU): moderate. A sustained GPU load generates more heat than ANE inference but is generally within what the M3 Air's passive heatsink can handle.
- MetaWhisp (ANE): coolest. ANE inference generates little heat because the Neural Engine is a fixed-function accelerator optimized for low-power AI workloads, unlike the general-purpose GPU.
Which Processing Mode Uses Least Battery: CPU vs GPU vs ANE?
Apple Silicon offers three inference paths for Whisper models:- CPU (via whisper.cpp): 12-18W for large-v3 models. Slowest and least efficient. Used as fallback when Metal and Core ML aren't available. Avoid for battery-constrained workflows.
- GPU (via Metal Performance Shaders): 6-9W for large-v3. Good balance of speed and compatibility. Works on all Apple Silicon Macs. Used by Wispr Flow, Aiko, and most third-party Whisper apps.
- ANE (via Core ML): 0.8-1.2W for large-v3-turbo. Most efficient but requires Core ML compilation and macOS 14.0+. Used by MetaWhisp and Apple's built-in Live Speech feature (which uses a smaller Whisper variant).
| Inference Path | Approx. Power (W) for large-v3 | Relative Efficiency | Examples |
|---|---|---|---|
| CPU (whisper.cpp) | 12-18 W | Least efficient | MacWhisper (CPU mode), generic CLIs |
| GPU (Metal) | 6-9 W | Middle | Wispr Flow, Aiko, Buzz |
| ANE (Core ML) | ~0.8-1.2 W (model) | Most efficient | MetaWhisp, Apple Live Speech |
Apple's Neural Engine is a fixed-function matrix accelerator with 128-bit SIMD units optimized for INT8 and FP16 operations. Whisper's encoder and decoder are transformer models that map efficiently to ANE's architecture, achieving 90-95% theoretical peak utilization. The GPU, by contrast, is a general-purpose shader processor that must context-switch between graphics, compute, and ML workloads, reducing efficiency. According to Apple's Core ML compute units documentation, ANE inference can be 8-12× more power-efficient than GPU for models that fit within ANE's constraints (≤6 GB weights, ≤512k tokens).
Does Cloud vs Local Voice-to-Text Matter for Battery?
Yes — cloud-based transcription draws meaningfully more battery than local inference, because it stacks several costs that local inference doesn't have:- Radio power: Wi-Fi draws far more during active uploads than when idle, and streaming audio for transcription keeps it in that high-power state.
- TLS encryption: HTTPS uploads require AES-GCM encryption, which adds CPU load during uploads (TLS 1.3 has no dedicated crypto offload in macOS).
- Network retry logic: Dropped packets, timeouts, and API rate limits trigger retries that keep the CPU and radio active longer than the nominal upload time.
- Dual-path fallback: Apps that run both cloud API calls and a local Whisper fallback pay both costs at once during network waits.
How to Check Your Mac's Battery Drain During Voice-to-Text
To measure your own app's battery impact on your specific Mac:- Charge to 100% and let the device cool to room temperature (15-20 minutes idle).
- Quit all apps except the voice-to-text tool you're testing.
- Open Terminal and run:
sudo powermetrics --samplers cpu_power --sample-rate 1000 -n 3600 > ~/powerlog.txt(thecpu_powersampler is more reliable thantasksfor sustained workloads). - Start a 60-minute dictation session.
- After 60 minutes, stop the dictation and wait 30 seconds, then press Ctrl+C in Terminal to stop
powermetrics. - Open
~/powerlog.txtand read the average combined power figures over the run. - Check battery percentage in System Settings → Battery. The difference from start (100%) to end is your total drain for that session.
Why does Activity Monitor show different power numbers than powermetrics?
Activity Monitor's "Energy Impact" column is a relative score (0-100) that factors in CPU time, GPU time, wake events, and network I/O. It's useful for comparing apps but doesn't show actual watts. powermetrics reports real power draw in milliwatts by reading CPU package power rails via SMC (System Management Controller). For battery drain calculations, use powermetrics. Activity Monitor is good for identifying which app is causing high energy impact, then you drill down with powermetrics for precise measurements.
Do background apps affect voice-to-text battery drain tests?
Yes — significantly. macOS background tasks (Spotlight indexing, Time Machine, iCloud sync, Photos face detection) can add 2-5W baseline load during "idle" periods. That's why isolation is critical: quit all apps, disable network except for cloud-mode tests, and wait for Spotlight to finish indexing before starting the test. Check Activity Monitor → CPU tab and confirm mds_stores (Spotlight), backupd (Time Machine), and photoanalysisd (Photos) are idle (<0.5% CPU) before running benchmarks. Background noise can shift results by 20-40%.
Does screen brightness affect voice-to-text battery life?
Not directly, but indirectly yes. The M3 Air's display power scales with brightness, and a higher-brightness screen adds to total system draw. For voice-to-text workflows, most users keep the app in the background and work in a text editor (Mail, Notes, VS Code). An app that constantly animates waveforms or live transcripts in a full window keeps the display active and busy, whereas a compact HUD overlay with minimal animation updates the screen less. For long dictation sessions, lowering brightness and minimizing on-screen animation helps, or use an external monitor (which draws power from AC, not battery).
Is Whisper large-v3 more battery-hungry than smaller models?
Yes — larger models do more compute per second of audio. Whisper large-v3 has 1.55 billion parameters; small has 244 million; tiny has 39 million. Because power scales with the amount of computation, large-v3 uses more energy per second than the smaller models. However, large-v3's higher accuracy means fewer corrections and re-dictations, which can offset the higher inference cost in real-world use. The best model size depends on your workflow: large-v3 for first-draft dictation where accuracy matters most, a smaller model for quick notes or commands where speed and battery matter more.
Can I use ANE inference with whisper.cpp or other open-source tools?
Not directly. ANE dispatch requires Core ML .mlpackage format and the Core ML APIs in Swift or Objective-C. whisper.cpp uses Metal GPU shaders, which bypass ANE. To use ANE, you must compile Whisper to Core ML via Apple's coremltools Python library, then integrate the .mlpackage into a macOS app using Core ML APIs. That's non-trivial for CLI users. MetaWhisp ships pre-compiled Core ML models and handles the integration, which is why it achieves ANE efficiency out of the box. Open-source alternatives like swift-coreml-transformers can wrap Core ML models but require Swift development skills.
Real-World Battery Life Across a Workday
For a typical remote-work pattern — dictating on and off through the day rather than continuously — the architecture you choose compounds over hours. An ANE-based app, drawing the least power per session and generating the least heat, is the one most likely to carry a fanless M3 Air through a full workday of intermittent dictation on a single charge. A GPU-based app uses more, and a cloud-hybrid app uses the most, so the more your day depends on dictation, the more the gap matters.Pro tip: Enable Low Power Mode (System Settings → Battery → Low Power Mode) during long dictation sessions. It caps peak CPU/GPU frequency and reduces system power across the board, extending runtime for any of these apps. It has little effect on ANE inference but lowers GPU clocks, which can slightly increase latency for GPU-based tools — usually a worthwhile trade for longer unplugged time.
Battery Drain Recommendations by Use Case
By daily dictation load and constraints:- Freelancers / remote workers (3-6 hrs/day dictation): Use MetaWhisp or another ANE-based tool. GPU and cloud tools are more likely to require midday charging, which disrupts focus.
- Students / researchers (1-2 hrs/day): Wispr Flow or MetaWhisp both work. GPU inference is acceptable for shorter sessions and is unlikely to trigger thermal throttling.
- Lawyers / medical professionals (HIPAA/compliance): On-device tools are preferable for keeping audio local. MetaWhisp or Wispr Flow; avoid cloud APIs for sensitive audio. ANE inference is preferred for all-day depositions or clinic notes.
- Occasional users (<30 min/day): Any tool works. Cloud APIs (SuperWhisper, Otter) are convenient for short sessions and won't drain battery noticeably at that volume.
- Content creators / writers (8+ hrs/day): An ANE-based tool is the practical choice for the longest unplugged runtime on fanless Macs. More RAM (16GB+) can also help by reducing memory-pressure overhead.

Author's Take: Why I Optimized MetaWhisp for ANE
I'm Andrew Dyuzhov, solo founder of MetaWhisp. I built this tool because I rely on dictation heavily in my own work and wanted it to run all day on a fanless Mac without draining the battery. Many of the voice-to-text apps I looked at run on the GPU or in the cloud, both of which are heavier on battery than on-device Neural Engine inference. Apple Neural Engine support isn't trivial: it means compiling Whisper to Core ML, working through memory layouts, and fitting the model within the Neural Engine's constraints. The payoff is the lowest-power inference path available on Apple Silicon — which, on a fanless Mac, is the difference between working unplugged through the day and hunting for outlets. If you're on a fanless Mac and you dictate for more than a couple of hours a day, try MetaWhisp free for 14 days. You can confirm the battery difference yourself in Activity Monitor and with the measurement steps above on your own hardware.Related Reading: Voice-to-Text on Mac
- 7 Best Wispr Flow Alternatives for Mac (2026) — Compare local and cloud voice-to-text tools with battery benchmarks
- MetaWhisp vs Wispr Flow: Accuracy, Speed, Privacy (2026) — Head-to-head comparison on M3 devices
- On-Device Transcription: How MetaWhisp Uses Apple Neural Engine — Technical deep dive on Core ML optimization
- Processing Modes: CPU vs GPU vs ANE for Whisper — Architecture guide for inference paths
Try MetaWhisp Free on Your M3 Mac
See the battery difference yourself. MetaWhisp runs Whisper large-v3-turbo on the Apple Neural Engine — the most power-efficient inference path on Apple Silicon, lower-draw than GPU/Metal apps like Wispr Flow and far below cloud-hybrid modes. No cloud upload, no API costs, and minimal heat on fanless Macs. Free 14-day trial, no credit card required.