What Did OpenAI Actually Ship on May 7, 2026?
OpenAI released three new audio models in one launch: GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper. The full details are in OpenAI's voice intelligence announcement. The three models do different things:- GPT-Realtime-2 — Voice reasoning model with GPT-5-class capabilities. 128,000-token context window. Scored 15.2 percentage points higher than its predecessor on Big Bench Audio at high reasoning effort. Used for live voice agents and conversational interfaces.
- GPT-Realtime-Translate — Streaming live translation across 70+ input languages, with continuous output as the speaker talks.
- GPT-Realtime-Whisper — Dedicated streaming speech-to-text. Converts audio to text token-by-token in real time instead of waiting for 30-second audio chunks. Priced at $0.017 per minute.
Does GPT-Realtime-Whisper Run On My Mac?
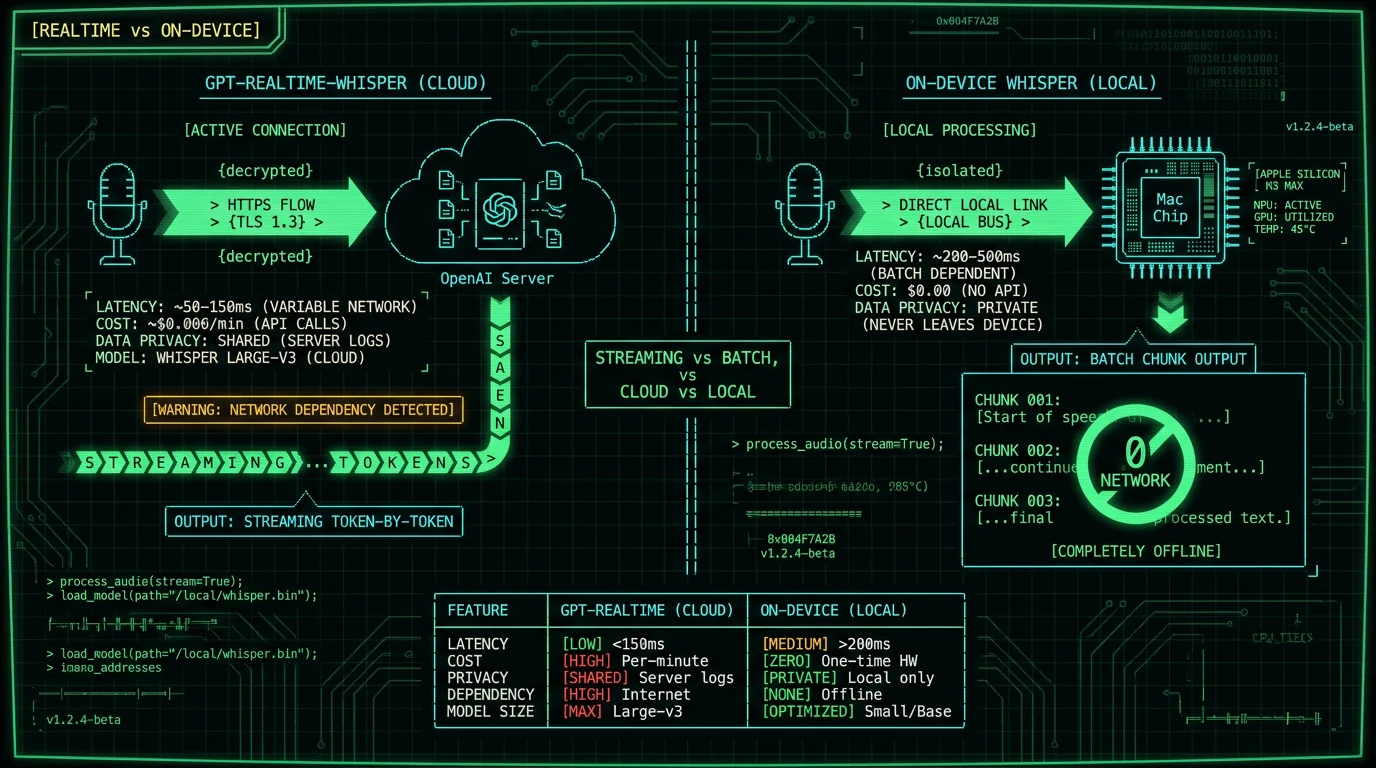
No. GPT-Realtime-Whisper runs in OpenAI's cloud. You access it through the OpenAI Realtime API by sending audio to OpenAI's servers and receiving streaming text back. Your Mac sends and receives data — it does not run the model. This is the most important practical difference from open-source Whisper. The original Whisper model is published under MIT license on OpenAI's GitHub with downloadable weights. You can run it on any machine that has enough memory. Apps like MetaWhisp, MacWhisper, and SuperWhisper all do this — they bundle Whisper weights and run inference on your Mac's CPU, GPU, or Apple Neural Engine. GPT-Realtime-Whisper has no published weights. There's no model file to download. The only way to use it is through OpenAI's API, which means:- Audio leaves your Mac and travels to OpenAI's servers
- You pay per minute of audio processed
- You need an internet connection
- OpenAI sees and may retain your audio per their data policies
How Much Does GPT-Realtime-Whisper Cost vs Free On-Device Whisper?
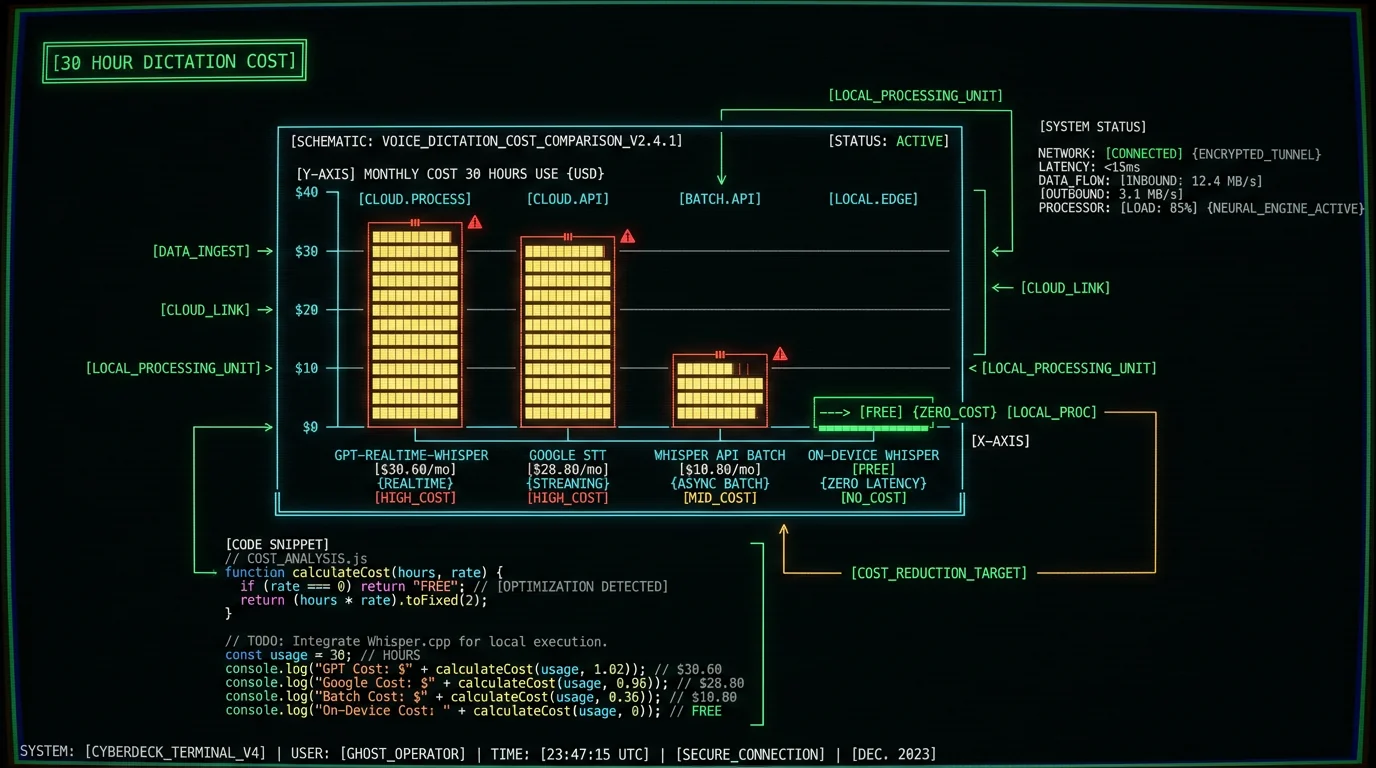
The pricing comparison is stark. Per OpenAI's pricing page:| Tool | Cost per minute | Monthly cost (30 hours/month) |
|---|---|---|
| GPT-Realtime-Whisper API | $0.017 | $30.60 |
| OpenAI Whisper API (batch) | $0.006 | $10.80 |
| Google Cloud Speech-to-Text default | $0.016 | $28.80 |
| On-device Whisper via MetaWhisp | $0 | $0 |
| On-device Whisper via MacWhisper | $0 | $0 (after $29 one-time) |
| Wispr Flow subscription | ~$0.50/min equivalent | $15/mo (capped use) |
Is GPT-Realtime-Whisper More Accurate Than Whisper large-v3?
Yes, but the gain concentrates in specific failure modes rather than across the board. The accuracy improvement reported by OpenAI is "approximately 90% fewer hallucinations" in their internal test using real-world background noise and varying silence intervals. What this means in practice:- Clean studio audio, native English speakers — Both produce comparable transcripts. The difference is imperceptible for most use cases.
- Audio with long silence intervals — Original Whisper sometimes invents phrases ("thanks for watching", "subscribe", song lyrics). GPT-Realtime-Whisper handles silence cleanly.
- Noisy environments (cafes, cars, open offices) — GPT-Realtime-Whisper degrades more gracefully on background noise.
- Multi-speaker recordings — Streaming architecture handles speaker transitions better than batch chunks.
- Code-switching mid-sentence — Both handle this with auto-detection, but GPT-Realtime-Whisper's reasoning capability helps with rare languages.
What About Latency? Is Streaming Actually Faster?
Yes, for one specific use case: live captions and real-time transcription where you need text appearing as the speaker talks. Original Whisper has built-in latency because it processes 30-second audio chunks — you wait for a chunk to fill, then wait for inference to complete, then text appears. The end-to-end delay can be 1-4 seconds for the first token. GPT-Realtime-Whisper streams tokens as audio arrives. Per the latent.space analysis, first-token latency is in the 100-400 millisecond range, plus network round-trip from your Mac to OpenAI's servers (typically 30-200ms depending on geography). For Mac dictation, this difference is smaller than it sounds:- Personal dictation in a text field — Most Mac apps use Whisper in "press, speak, release" mode. The user finishes speaking, then text appears. End-to-end latency is dominated by the user's speaking time, not Whisper's processing time. Streaming doesn't help.
- Live captions during a call or video — Streaming matters. GPT-Realtime-Whisper's continuous output is better for captions.
- Real-time meeting transcription — Streaming helps for live display but most users review meeting transcripts after, not during. Batch is fine.
- Voice agents and conversational AI — Streaming is essential. GPT-Realtime-2 paired with GPT-Realtime-Whisper enables sub-second voice agent responses.
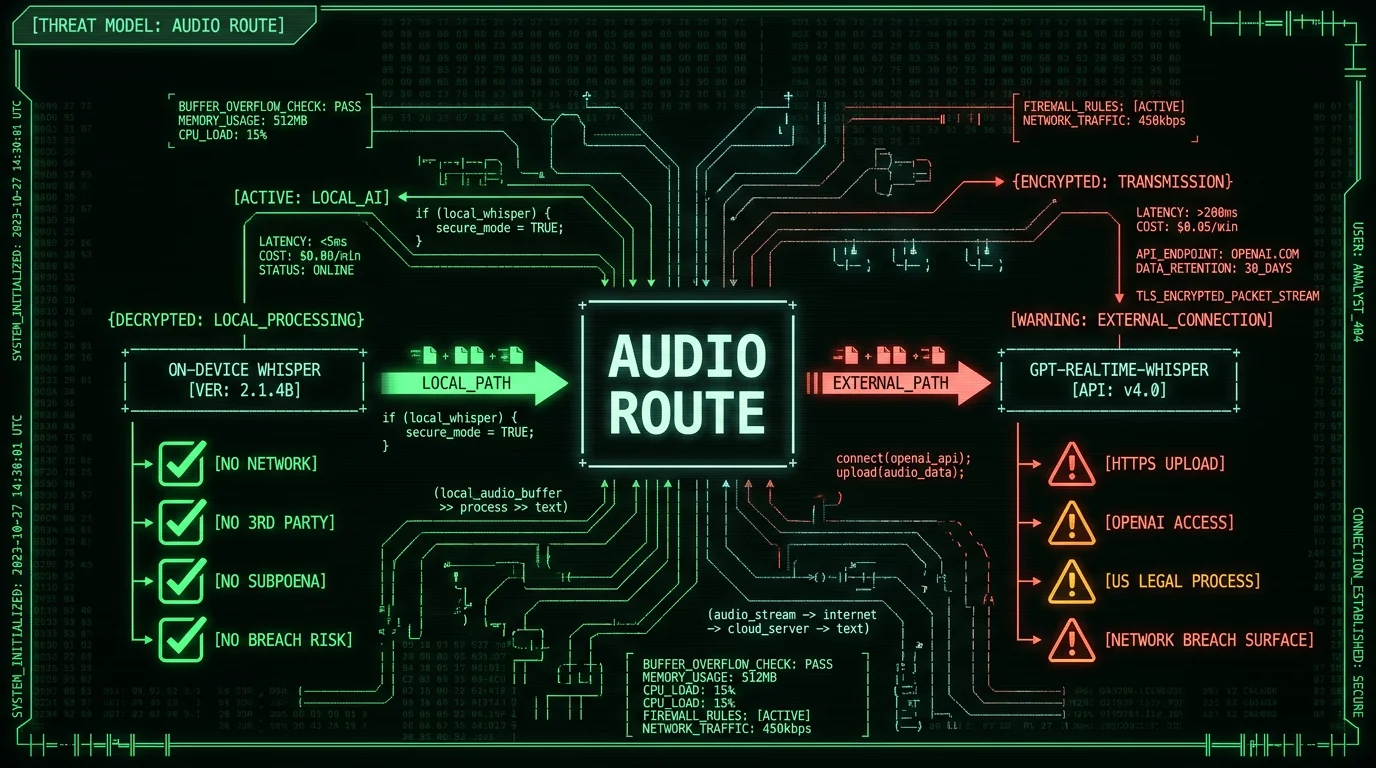
What Are the Privacy Implications of GPT-Realtime-Whisper?
Every minute of audio you send to GPT-Realtime-Whisper travels to OpenAI's servers, gets processed there, and returns to your Mac as text. This architectural reality has direct privacy consequences:- Audio leaves your device — there's no architectural way around it
- OpenAI has access to your audio during processing
- OpenAI may retain audio per their data retention policies
- OpenAI's HIPAA-eligible service requires a signed Business Associate Agreement and a specific Enterprise tier setup
- Audio uploaded to US servers is subject to US legal process (subpoenas, NSL orders)
- Network breaches between your Mac and OpenAI are a potential exposure
When Should I Use GPT-Realtime-Whisper Over On-Device Whisper?
The decision tree comes down to which constraint dominates your use case:- Use GPT-Realtime-Whisper when: building a live voice agent or real-time captioning product, processing audio for users who explicitly consent to cloud upload, needing sub-200ms streaming output, working with multi-speaker streaming audio, building an enterprise SaaS where per-minute API cost is acceptable, or operating in a regulated environment with a signed BAA with OpenAI.
- Use on-device Whisper when: dictating on your personal Mac, transcribing audio you'd consider confidential, working without consistent internet, doing high-volume batch transcription where cloud cost adds up, or running on user hardware where you can't add per-user marginal cost.
- Use both when: building a tiered product where free tier is on-device and premium tier offers streaming cloud features, or running a fallback architecture where on-device handles 99% and cloud handles edge cases.
Why Is MetaWhisp Sticking with On-Device Whisper After This Launch?
I'm Andrew Dyuzhov, solo founder of MetaWhisp. I built MetaWhisp on Whisper large-v3-turbo running on Apple Neural Engine because three constraints decided the architecture:- Free for users without ads or data collection — On-device inference has zero marginal cost per user. Cloud APIs charge per minute. To stay free, the math only works on-device.
- Privacy that users can verify — Telling users "we don't store your audio" is weak. Letting users run the app in airplane mode and verify zero network calls is strong. Only on-device architecture supports this.
- Works offline — Macs are mobile. Dictation that fails on flights, in cafes with weak WiFi, or in remote work locations is a UX problem on-device transcription doesn't have.
Frequently Asked Questions About GPT-Realtime-Whisper
Is GPT-Realtime-Whisper free?
No. GPT-Realtime-Whisper is a paid API at $0.017 per minute of audio processed per OpenAI's pricing page. There is no free tier separate from OpenAI's general API credits. For free transcription on Mac, use on-device Whisper via apps like MetaWhisp, MacWhisper, or whisper.cpp, which run the open-source Whisper model on your hardware at zero per-minute cost.
Can I download GPT-Realtime-Whisper weights to run locally?
No. OpenAI has not released GPT-Realtime-Whisper model weights. The only way to use it is through OpenAI's Realtime API, which requires uploading audio to OpenAI's servers. The original Whisper model (Whisper large-v3, large-v3-turbo, etc.) remains downloadable under MIT license on OpenAI's GitHub for local use.
How does GPT-Realtime-Whisper compare to Apple Dictation?
GPT-Realtime-Whisper is a cloud API service for developers and SaaS products, not a consumer dictation tool. Apple Dictation is a system-level Mac feature that runs on-device on Apple Silicon. They serve different use cases: GPT-Realtime-Whisper for building voice products at scale, Apple Dictation for personal Mac dictation. Apple Dictation is free; GPT-Realtime-Whisper costs $0.017 per minute.
Does GPT-Realtime-Whisper work for Mac dictation apps?
Some Mac dictation apps may integrate GPT-Realtime-Whisper as a premium cloud-streaming tier. As of May 2026, no major Mac dictation app has announced GPT-Realtime-Whisper integration. The economics make it hard to integrate into free apps because per-minute cost would need to pass to users. For paid apps already charging subscriptions, integration is more feasible.
Will GPT-Realtime-Whisper replace original Whisper?
No. They serve different use cases. GPT-Realtime-Whisper is optimized for streaming cloud applications where audio uploads to OpenAI servers are acceptable. Original Whisper remains the standard for on-device transcription, batch processing, and any workflow where audio cannot leave the device. The open-source Whisper model continues to be developed in the community for local deployment.
Is GPT-Realtime-Whisper HIPAA-compatible?
Only on OpenAI's Enterprise tier with a signed Business Associate Agreement. The default API tier is NOT HIPAA-compatible. For healthcare workflows on Mac, the simpler path is on-device Whisper via apps like MetaWhisp, which sidesteps the BAA requirement because audio never leaves the device. No third party access means no contractual coverage needed.
What languages does GPT-Realtime-Whisper support?
GPT-Realtime-Whisper supports the same language set as the underlying Whisper model — 99 languages including English, Spanish, Mandarin, Hindi, Arabic, French, German, Portuguese, Japanese, Russian. GPT-Realtime-Translate, the sibling model, supports 70+ input languages for streaming live translation. For Mac dictation in any of these languages, on-device Whisper handles them too.
About the Author
Andrew Dyuzhov is the solo founder and CEO of MetaWhisp, a free on-device voice-to-text app for macOS running Whisper large-v3-turbo on Apple Neural Engine. MetaWhisp's architecture decision to stay on-device — rather than route to cloud APIs like GPT-Realtime-Whisper — comes from three constraints: zero per-user marginal cost, user-verifiable privacy, and offline operation. Connect on X or GitHub.
Related Reading
- What Is Whisper large-v3-turbo? — the on-device model MetaWhisp uses
- Whisper vs Google Speech-to-Text — cloud STT comparison
- Private Voice-to-Text on Mac — on-device architecture deep-dive
- Whisper Model Sizes: Tiny to Turbo — pick the right local Whisper variant
- Why Whisper Hallucinates in Silence — the failure mode GPT-Realtime-Whisper improves on