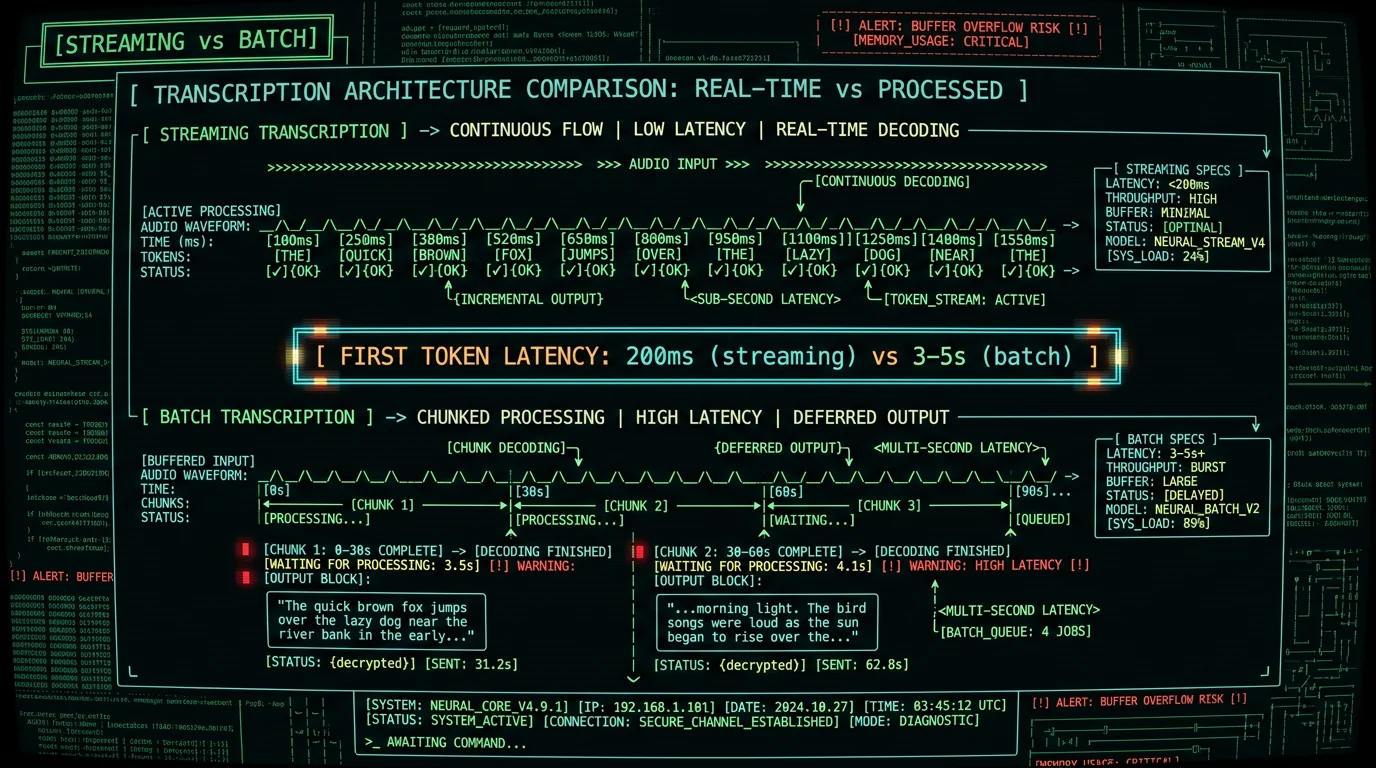
What Is Streaming Transcription and How Does It Differ from Batch?
Streaming transcription processes audio continuously, outputting text tokens as they're recognized. Batch transcription waits for a chunk of audio (typically 30 seconds) before processing, then outputs the full transcript for that chunk. The architectural difference shapes everything else:- Streaming — Audio enters the model in small frames (often 100ms). The model maintains state across frames and outputs tokens incrementally. Text appears character-by-character or word-by-word as you speak.
- Batch — Audio buffers for 30 seconds, then enters the model as a single unit. The model processes the entire chunk and outputs the full transcript at once. Text appears in blocks every 30 seconds (or when the user stops speaking and the chunk closes).
Which Mac Tools Support Streaming Transcription?
The current landscape as of May 2026:| Tool | Streaming | Location | Pricing |
|---|---|---|---|
| OpenAI GPT-Realtime-Whisper | Native streaming | Cloud (OpenAI servers) | $0.017/min |
| Google Cloud Speech-to-Text Streaming | Native streaming | Cloud (Google servers) | $0.016/min |
| AssemblyAI Streaming | Native streaming | Cloud | $0.015/min |
| Apple Speech Recognition framework | Native streaming (on-device on M-series) | On-device or Apple cloud | Free (system API) |
| whisper.cpp with streaming wrapper | Chunked streaming (community) | On-device | Free, open-source |
| Standard Whisper (large-v3, turbo) | Batch only (chunked) | On-device | Free, MIT license |
| MetaWhisp | Press-and-hold dictation (effectively batch per session) | On-device | Free |
| Wispr Flow | Press-and-hold dictation with streaming display | Cloud | ~$15/month |
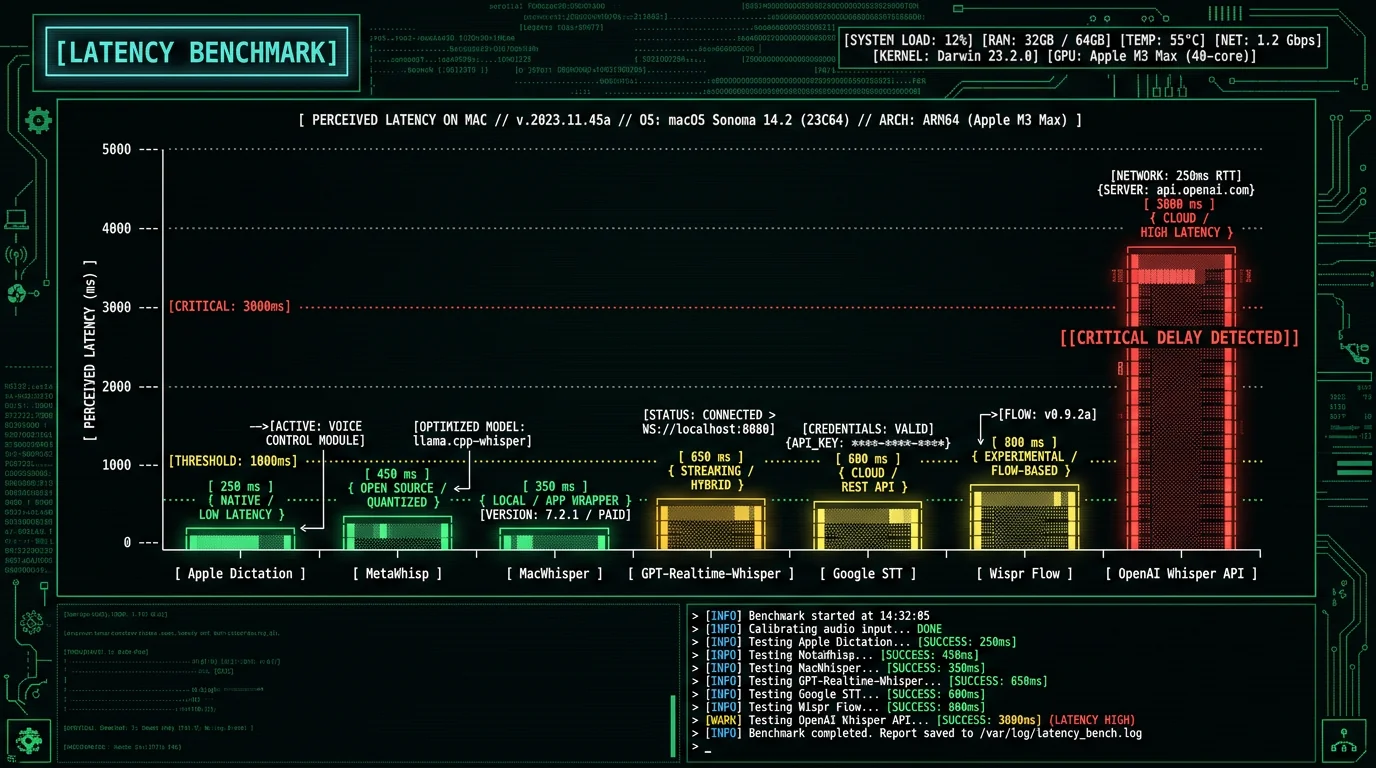
What Are the Real Latency Numbers on Mac?
End-to-end latency for a dictated sentence — measured from when you start speaking to when text appears:- Apple Dictation (Enhanced, on-device M3): 50-200ms first-word display, full sentence within 1 second of release
- Whisper large-v3-turbo on Apple Neural Engine (MetaWhisp, MacWhisper): ~150-400ms per 30-second chunk processing, text appears in user-perceived "real-time" because chunks close on hotkey release
- GPT-Realtime-Whisper (cloud streaming): 100-400ms first-token plus 30-200ms network round-trip = ~150-600ms total
- Google Cloud STT Streaming: 100-400ms first-token plus network = similar to GPT-Realtime
- Wispr Flow (cloud): 200-800ms typical, varies with network
- OpenAI Whisper API (batch): Audio uploaded, processed in 1-2× audio length, then returned = several seconds for short audio
When Does Streaming Actually Matter on Mac?
Streaming is meaningfully better than batch for these specific use cases:- Live captions during a video call, lecture, or presentation — User needs to see text as the speaker talks, not after they finish
- Real-time voice agents and conversational AI — Sub-second response time requires streaming both speech recognition and LLM inference
- Multi-speaker meeting transcription with live display — Streaming lets attendees see who said what in real time
- Accessibility tools for deaf and hard-of-hearing users — Live captions are an accessibility need where batch latency is exclusionary
- Live translation — Streaming speech-to-text + streaming translation lets users hear/see translation as the speaker talks
- Voice-controlled live interfaces — Game commands, voice-driven cockpit controls, real-time voice interactions
- Personal dictation — Press hotkey, speak, release, paste. Batch handles this with sub-second perceived latency on Apple Neural Engine
- Voice memo transcription — Recording is already done, file is on disk, transcription speed isn't user-blocking
- Meeting recording transcription after the fact — Meeting is over, processing in batch is fine
- Podcast episode transcription — Hours of audio, no real-time requirement
- Lecture recording transcription — Same — recorded content, batch is appropriate
How Does whisper.cpp Streaming Compare to GPT-Realtime-Whisper?
The open-source whisper.cpp project includes a streaming mode that buffers overlapping audio windows and runs Whisper inference on each window with continuity. It's the closest local equivalent to GPT-Realtime-Whisper. Comparison:- Accuracy — whisper.cpp streaming uses standard Whisper weights, accuracy is on par with batch Whisper (3.5%-5.7% WER for large variants). GPT-Realtime-Whisper has improved hallucination handling but similar overall accuracy on clean speech.
- Latency — whisper.cpp streaming on Apple Neural Engine produces partial transcripts every 200-500ms. GPT-Realtime-Whisper produces tokens at 100-400ms with no chunking artifacts.
- Stability — whisper.cpp streaming sometimes revises earlier text when context changes. GPT-Realtime-Whisper is more stable token-by-token because the model is purpose-built.
- Privacy — whisper.cpp runs entirely on-device. GPT-Realtime-Whisper uploads audio to OpenAI.
- Cost — whisper.cpp is free. GPT-Realtime-Whisper is $0.017/min.
- Setup — whisper.cpp requires Terminal usage and build flags. GPT-Realtime-Whisper requires OpenAI API key and HTTP client.
What Is Apple's Native Streaming Speech Recognition?
macOS exposes a Speech Recognition framework that Mac developers can use for on-device streaming speech recognition. Per Apple's documentation, the framework supports:- Live audio buffer transcription with partial results
- On-device processing on Apple Silicon (M-series) Macs
- SFSpeechRecognizer API for developers
- The same dictation model that powers Apple Dictation system-wide
- No custom vocabulary support (same model as Apple Dictation)
- Limited language coverage compared to Whisper (covers Apple's supported dictation languages, not all 99 Whisper languages)
- Accuracy on technical vocabulary and accents matches Apple Dictation (lower than Whisper large-v3 for some content types)
- Silence cutoff behavior inherited from Apple Dictation
Why Doesn't MetaWhisp Use Streaming Architecture?
I'm Andrew Dyuzhov, founder of MetaWhisp. MetaWhisp uses press-and-hold dictation with batch Whisper inference on Apple Neural Engine. Three reasons this is the right architecture for the use case:- Press-and-hold matches user mental model — Mac users grew up on push-to-talk dictation. Streaming continuous transcription has no clear "session" boundary, which complicates the UX. Press-and-hold is universally understood
- Batch on Apple Neural Engine is fast enough — Whisper large-v3-turbo processes 30 seconds of audio in 150-400ms on M-series ANE. User-perceived latency from release to text-appears is sub-second. Streaming wouldn't be visibly faster for the use case
- Stability over chunking artifacts — Streaming Whisper revises earlier text as new context arrives. For dictation into text fields where text is committed as it appears, revisions break the workflow. Batch produces finalized text that doesn't change
Frequently Asked Questions About Streaming Transcription
What is streaming transcription?
Streaming transcription processes audio continuously and outputs text tokens as they're recognized, rather than waiting for full audio chunks. Text appears as you speak, with first-token latency typically 100-400 milliseconds. Contrasts with batch transcription which processes 30-second chunks and outputs after the chunk completes. Streaming matters for live captions, voice agents, and real-time applications.
Can Whisper stream in real-time on Mac?
Standard Whisper is a batch model that processes 30-second chunks. The whisper.cpp open-source project has streaming wrappers using overlapping windows for continuous output. OpenAI's GPT-Realtime-Whisper (May 2026) is a native streaming model but runs in OpenAI's cloud at $0.017/min. For most personal Mac dictation, press-and-hold batch Whisper on Apple Neural Engine delivers sub-second perceived latency without needing streaming architecture.
Is GPT-Realtime-Whisper available for Mac?
Yes, via OpenAI Realtime API. Mac developers can integrate GPT-Realtime-Whisper by sending audio over HTTPS to OpenAI's servers and receiving streaming text tokens. As of May 2026, no major Mac dictation app has announced GPT-Realtime-Whisper integration. The cloud requirement and per-minute pricing make it less suitable for free consumer apps than on-device alternatives.
What's the latency of streaming transcription on Mac?
Depends on tool: Apple Dictation (Enhanced, on-device): 50-200ms first-word. Whisper on Apple Neural Engine batch: 150-400ms per chunk. GPT-Realtime-Whisper (cloud streaming): 100-400ms first-token plus 30-200ms network = 150-600ms. Google Cloud STT Streaming: similar to GPT-Realtime. Wispr Flow: 200-800ms typical. On-device batch on M-series is often faster perceived latency than cloud streaming.
Do I need streaming transcription for Mac dictation?
Usually no. Personal Mac dictation (press hotkey, speak, release, paste) is dominated by user speaking time, not processing time. Batch transcription on Apple Neural Engine produces sub-second perceived latency from release to text-appears. Streaming matters for live captions during meetings, real-time voice agents, accessibility tools, and live translation — not for personal dictation patterns.
What's the difference between streaming and real-time transcription?
"Streaming" describes the technical architecture: tokens output incrementally as audio arrives. "Real-time" is a user-experience claim about perceived speed. Streaming architecture enables real-time UX. But batch architecture can also produce real-time-feeling UX when chunks are small and processing is fast (Whisper on Apple Neural Engine). The terms overlap in marketing but have distinct technical meanings.
Is on-device streaming transcription possible on Mac?
Yes. Apple's Speech Recognition framework supports on-device streaming on Apple Silicon Macs. whisper.cpp has community streaming wrappers. The trade-off: Apple's API has limited language support, whisper.cpp streaming requires technical setup and may revise earlier tokens. For most users, on-device batch Whisper via apps like MetaWhisp or MacWhisper delivers fast enough latency without needing true streaming.
About the Author
Andrew Dyuzhov is the solo founder and CEO of MetaWhisp, a free on-device voice-to-text app for macOS that runs Whisper large-v3-turbo on Apple Neural Engine. MetaWhisp uses batch chunked Whisper inference rather than streaming architecture because the press-and-hold dictation pattern doesn't need streaming — batch on Apple Neural Engine delivers sub-second perceived latency that streaming wouldn't visibly improve. Connect on X or GitHub.
Related Reading
- GPT-Realtime-Whisper vs On-Device Whisper — direct comparison of new streaming model
- What Is Whisper large-v3-turbo? — the local Whisper variant powering Mac apps
- Whisper vs Google Speech-to-Text — streaming cloud STT comparison
- Private Voice-to-Text on Mac — on-device architecture
- Whisper Model Sizes — pick the right Whisper for your latency target